分布式事务
分布式理论
CAP 理论
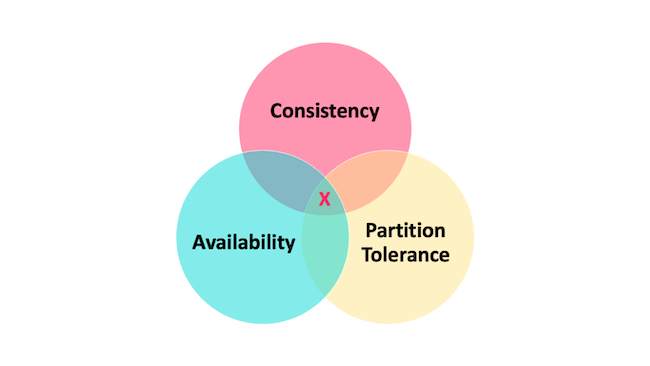
CAP理论的适用前提是多个节点之间是相同的服务,即多个副本节点组成的集群。在这种情况下,当发生网络分区时,副本节点之间的数据同步会受到影响,需要在一致性(Consistency)和可用性(Availability)之间进行权衡。
当谈论分区容错性时,我们指的是分布式系统在发生网络分区的情况下,仍然能够正常运行并对外提供服务。
网络分区是指在分布式系统中,节点之间的通信被中断或者延迟非常严重,导致节点无法互相通信。这可能是由于网络故障、网络拥塞、节点故障等原因引起的。
为了实现分区容错性,分布式系统通常采取以下策略:
- 副本复制:将数据在多个节点之间进行复制,以保证数据的可用性和冗余。当发生网络分区时,即使某些节点无法与其他节点通信,仍然可以通过其他副本节点继续提供服务。
- 容错机制:引入容错机制,例如故障检测和自动故障恢复,以检测和处理节点故障,保证系统的可用性。这可以包括使用心跳机制进行节点健康状态的监测,以及使用故障转移和数据备份等技术来保证数据的完整性和可用性。
- 分区感知设计:在系统设计阶段,考虑到网络分区的可能性,采用分区感知的设计策略。这包括将节点划分为不同的分区或区域,并在设计时考虑不同分区之间的通信需求和容错性要求。这样,即使发生网络分区,系统仍然可以在各个分区内部继续运行。
- 优雅降级和限流:当发生网络分区时,系统可能无法完全提供正常的服务。为了保证整个系统的稳定性,可以通过优雅降级和限流等手段,降低对外部用户的影响,防止系统崩溃。
综上所述,分区容错性是通过副本复制、容错机制、分区感知设计和优雅降级等方式,在发生网络分区时保证分布式系统的可用性和稳定性。
思考如何保证 CA ?
在分布式系统中,同时保证一致性和可用性是非常困难的,因为它们在某些情况下是互斥的。然而,有一些机制和技术可以帮助我们在一定程度上兼顾一致性和可用性。
- 异步复制:使用异步复制机制可以在保证可用性的同时,实现数据的一致性。在这种情况下,写操作在主节点上完成后,可以立即返回给客户端,然后异步地将数据复制到其他副本节点上。这样可以提高系统的可用性,但是可能会出现一段时间内的数据不一致。
- 副本机制:通过在系统中使用副本机制,可以在不同的节点上存储数据的副本,以提高系统的可用性和容错性。当一个节点发生故障时,其他节点上的副本可以继续提供服务。副本机制可以使用一致性协议来保证数据的一致性,例如使用分布式一致性算法(如Paxos、Raft)来达成共识。
- 分区容错:将系统分为多个分区,每个分区可以独立运行,这样即使一个分区发生故障,其他分区仍然可以提供服务。分区容错可以提高系统的可用性,但可能会导致分区之间的数据一致性问题。在这种情况下,可以使用一致性协议来解决分区之间的一致性问题。
- 最终一致性:最终一致性是一种弱一致性模型,它允许在一段时间内的数据副本之间存在不一致,但最终会达到一致的状态。通过使用最终一致性模型,可以在一定程度上权衡一致性和可用性。最终一致性可以通过版本控制、时间戳等机制来实现。
需要注意的是,在某些情况下,我们可能不需要完全强调一致性,而是更注重可用性。在实际应用中,根据具体的业务需求和系统特点,我们需要权衡和取舍,选择适当的一致性模型和技术,以满足系统的需求。
也就是说,即使没有出现网络分区,也不能严格保证一致性和可用性是吧?因为无论是异步复制还是副本机制,在复制数据到其他节点的过程中,如果其他节点被访问数据,都会出现数据不一致的情况是吧?只是保证了可用性。
- 即使没有网络分区,也不能严格保证一致性和可用性。在分布式系统中,一致性和可用性通常是一种权衡。无论是异步复制还是副本机制,都存在一定的延迟,导致在数据复制到其他节点的过程中可能会出现数据不一致的情况。这是因为在复制的过程中,如果其他节点被访问数据,可能会读取到不同步的数据。
- 在一些场景中,我们可能会选择牺牲一致性来换取更高的可用性。例如,许多互联网应用程序更注重可用性,而对于数据的一致性要求较低。在这种情况下,系统可以容忍一段时间内的数据不一致,而保持可用性。
- 然而,对于一些关键业务或数据一致性要求较高的系统,我们可能会采取更严格的一致性机制,并可能牺牲一些可用性。比如银行业务。
总之,在分布式系统中,一致性和可用性之间是一个复杂的折中问题,需要根据具体情况进行权衡和取舍。
如果系统发生“分区”,我们要考虑选择 CP 还是 AP。如果系统没有发生“分区”的话,我们要思考如何保证 CA 。
BASE 理论
即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。
BASE 理论本质上是对 CAP 的延伸和补充,更具体地说,是对 CAP 中 AP 方案的一个补充。
AP 方案只是在系统发生分区的时候放弃一致性,而不是永远放弃一致性。在分区故障恢复后,系统应该达到最终一致性。这一点其实就是 BASE 理论延伸的地方。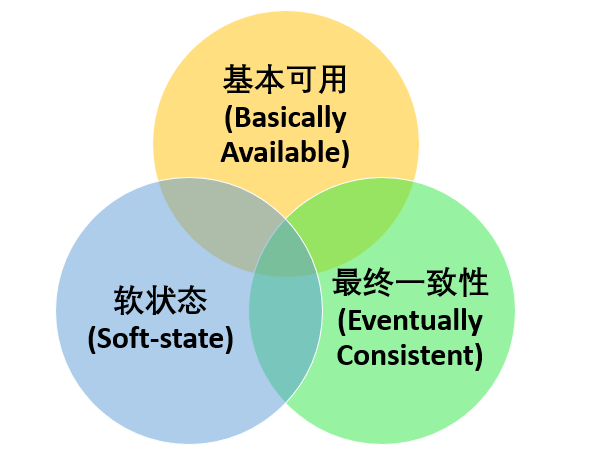
基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性。但是,这绝不等价于系统不可用。
什么叫允许损失部分可用性呢?
- 响应时间上的损失: 正常情况下,处理用户请求需要 0.5s 返回结果,但是由于系统出现故障,处理用户请求的时间变为 3 s。
- 系统功能上的损失:正常情况下,用户可以使用系统的全部功能,但是由于系统访问量突然剧增,系统的部分非核心功能无法使用。
软状态指允许系统中的数据存在中间状态(CAP 理论中的数据不一致),并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。
最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
分布式一致性的 3 种级别:
- 强一致性:系统写入了什么,读出来的就是什么。
- 弱一致性:不一定可以读取到最新写入的值,也不保证多少时间之后读取到的数据是最新的,只是会尽量保证某个时刻达到数据一致的状态。
- 最终一致性:弱一致性的升级版,系统会保证在一定时间内达到数据一致的状态。
业界比较推崇是最终一致性级别,但是某些对数据一致要求十分严格的场景比如银行转账还是要保证强一致性。
分布式事务的定义
事务是一个程序执行单元,里面的所有操作要么全部执行成功,要么全部执行失败。在分布式系统中,这些操作可能是位于不同的服务中,那么如果也能保证这些操作要么全部执行成功要么全部执行失败呢?这便是分布式事务要解决的问题。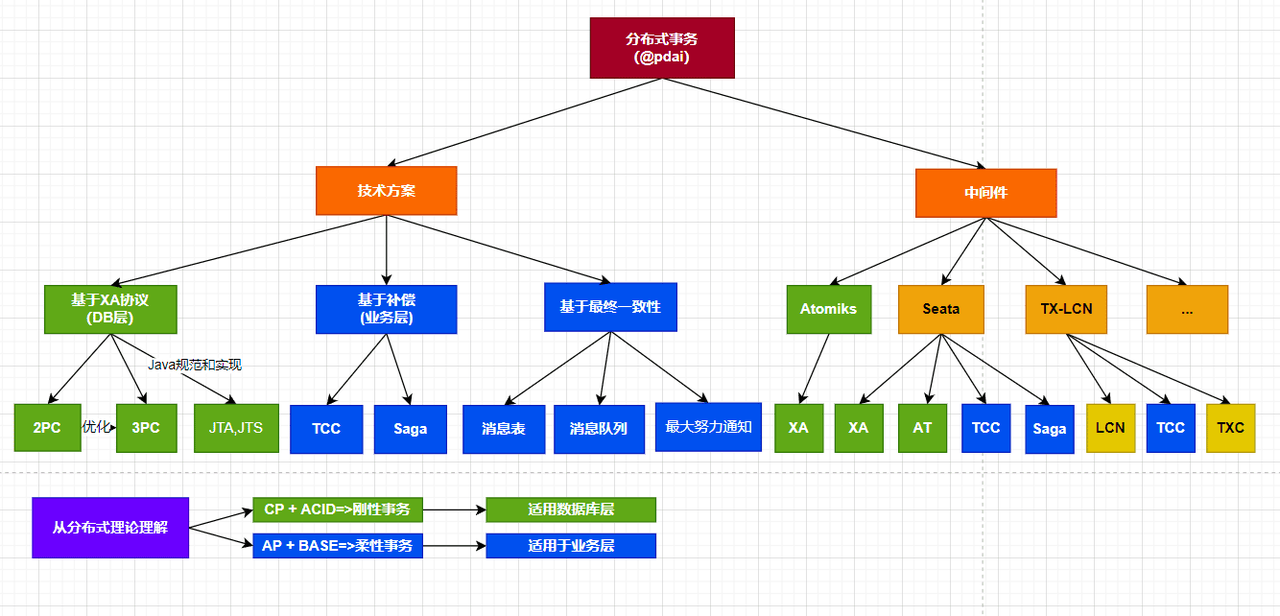
- 事务管理器:Transaction Manager
- 本地资源管理器:Resource Manager
- Java事务API(Java Transaction API)
- Java事务服务(Java Transaction Service)
XA协议的全称是X/Open Distributed Transaction Processing (DTP) XA协议。XA协议是一个由X/Open组织定义的分布式事务处理协议,用于协调和管理跨多个资源管理器(如数据库、消息中间件等)的分布式事务。XA协议提供了一种标准的接口和协议,使得应用程序能够在分布式环境中实现原子性、一致性和持久性的事务操作。它定义了一组事务管理器(Transaction Manager)和资源管理器(Resource Manager)之间的通信协议和接口规范,以实现分布式事务的提交和回滚操作。
刚性事务
2pc 和 3pc 都是由 XA 协议衍生而来的,主流的诸如Oracle、MySQL等数据库均已实现了XA接口。
两段提交(2PC)
简单而言:参与者(participant)用来管理资源,协调者(coordinator)用来协调事务状态
两段提交(2PC - Prepare & Commit)是指两个阶段的提交:
- 第一阶段: 准备阶段;
- 协调者向所有参与者发送 REQUEST-TO-PREPARE
- 当参与者收到REQUEST-TO-PREPARE 消息后, 它向协调者发送消息PREPARED或者NO,表示事务是否准备好;如果发送的是NO,那么事务要回滚;
- 第二阶段: 提交阶段。
- 协调者收集所有参与者的返回消息, 如果所有的参与者都回复的是PREPARED, 那么协调者向所有参与者发送COMMIT 消息;否则,协调者向所有回复PREPARED的参与者发送ABORT消息;
- 参与者如果回复了PREPARED消息并且收到协调者发来的COMMIT消息,或者它收到ABORT消息,它将执行提交或回滚,并向协调者发送DONE消息以确认。
两段提交(2PC)的缺点:
二阶段提交看似能够提供原子性的操作,但它存在着严重的缺陷:
- 网络抖动导致的数据不一致:第二阶段中协调者向参与者发送commit命令之后,一旦此时发生网络抖动,导致一部分参与者接收到了commit请求并执行,可其他未接到commit请求的参与者无法执行事务提交。进而导致整个分布式系统出现了数据不一致。
- 超时导致的同步阻塞问题:2PC中的所有的参与者节点都为事务阻塞型,当某一个参与者节点出现通信超时,其余参与者都会被动阻塞占用资源不能释放。
- 单点故障的风险:由于严重的依赖协调者,一旦协调者发生故障,而此时参与者还都处于锁定资源的状态,无法完成事务commit操作。虽然协调者出现故障后,会重新选举一个协调者,可无法解决因前一个协调者宕机导致的参与者处于阻塞状态的问题。
2PC只适用两个数据库(数据库实现了XA协议)之间;2PC有诸多问题和不便,在实践中一般很少使用。
三段提交(3PC)
三段提交(3PC)是对两段提交(2PC)的一种升级优化,
- 3PC在2PC的第一阶段和第二阶段中插入一个准备阶段。保证了在最后提交阶段之前,各参与者节点的状态都一致。
- 同时在协调者和参与者中都引入超时机制,当参与者各种原因未收到协调者的commit请求后,会对本地事务进行commit,不会一直阻塞等待,解决了2PC的单点故障问题,
- 但3PC还是没能从根本上解决数据一致性的问题。
3PC的三个阶段分别是CanCommit、PreCommit、DoCommit:
- CanCommit:协调者向所有参与者发送CanCommit命令,询问是否可以执行事务提交操作。如果全部响应YES则进入下一个阶段。
- PreCommit:协调者向所有参与者发送PreCommit命令,询问是否可以进行事务的预提交操作,参与者接收到PreCommit请求后,如参与者成功的执行了事务操作,则返回Yes响应,进入最终commit阶段。一旦参与者中有向协调者发送了No响应,或因网络造成超时,协调者没有接到参与者的响应,协调者向所有参与者发送abort请求,参与者接受abort命令执行事务的中断。
- DoCommit:在前两个阶段中所有参与者的响应反馈均是YES后,协调者向参与者发送DoCommit命令正式提交事务,如协调者没有接收到参与者发送的ACK响应,会向所有参与者发送abort请求命令,执行事务的中断。
3PC存在的问题:
3PC工作在同步网络模型上,它假设消息传输时间是有上界的,只存在机器失败而不存在消息失败。这个假设太强,现实的情形是,机器失败是无法完美地检测出来的,消息传输可能因为网络拥堵花费很多时间。同时, 说阻塞是相对, 存在协调者和参与者同时失败的情形下, 3PC事务依然会阻塞。实际上,很少会有系统实现3PC,多数现实的系统会通过复制状态机解决2PC阻塞的问题。比如,如果失败模型不是失败-停止, 而是消息失败(消息延迟或网络分区),那样3PC会产生不一致的情形。
3PC并没有完美解决2PC的阻塞,也引入了新的问题(不一致问题),所以3PC很少会被真正的使用。
柔性事务
柔性事务:分布式理论的AP,遵循BASE,允许一定时间内不同节点的数据不一致,但要求最终一致。
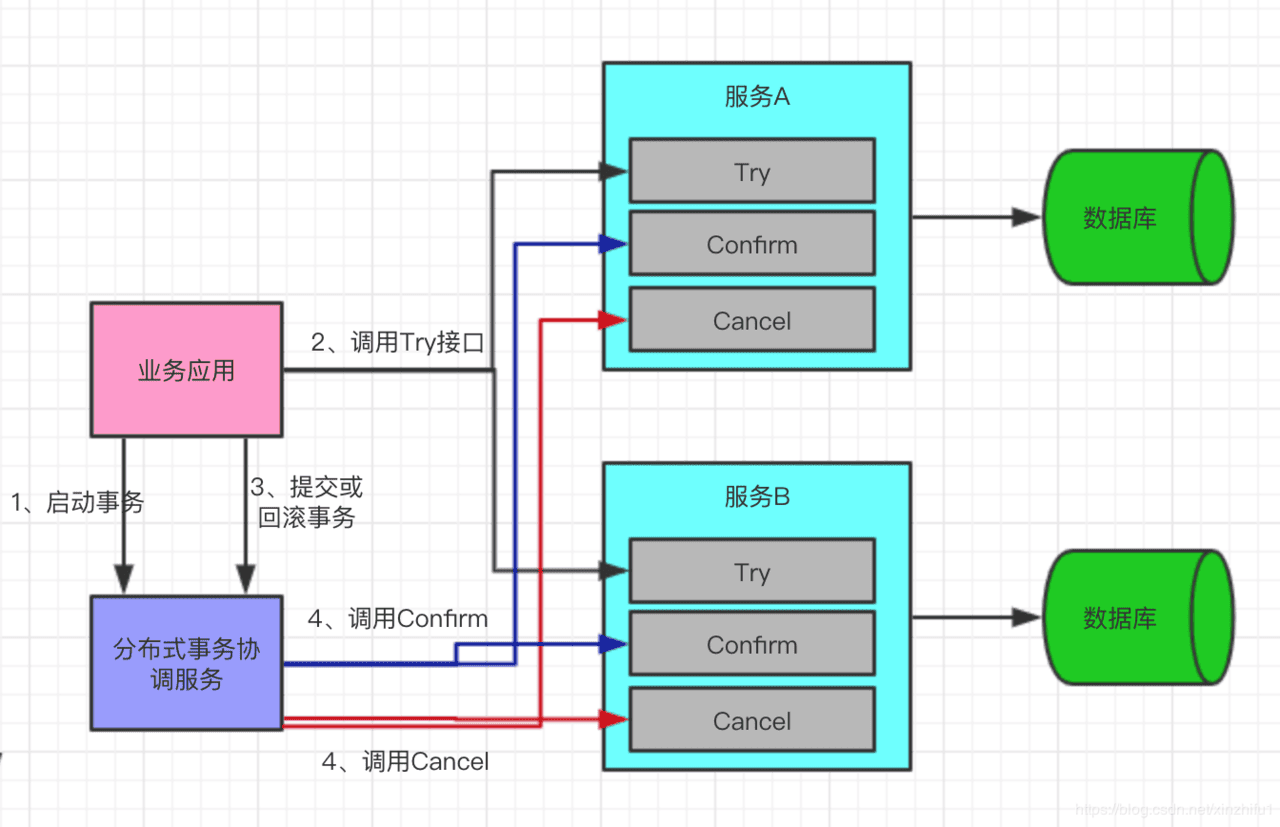
1、TCC(补偿事务)
TCC(Try-Confirm-Cancel)又被称补偿事务,TCC与2PC的思想很相似,事务处理流程也很相似,但2PC是应用于在DB层面,TCC则可以理解为在应用层面的2PC,是需要我们编写业务逻辑来实现。
TCC它的核心思想是:”针对每个操作都要注册一个与其对应的确认(Try)和补偿(Cancel)”。