
索引底层的底层实现
索引底层实现(数据结构)
Hash索引
- 哈希表是一种以键—值(key-value)存储数据的结构,我们只要输入待查找的值即 key,就可以找到其对应的值即 Value。哈希的思路很简单,把值放在数组里,用一个哈希函数把 key 换算成一个确定的位置,然后把 value 放在数组的这个位置。
- 不可避免地,多个 key 值经过哈希函数的换算,会出现同一个值的情况。处理这种情况的一种方法是,拉出一个链表。
- 哈希表这种结构适用于只有等值查询的场景,比如 Memcached 及其他一些 NoSQL 引擎。
B 树索引
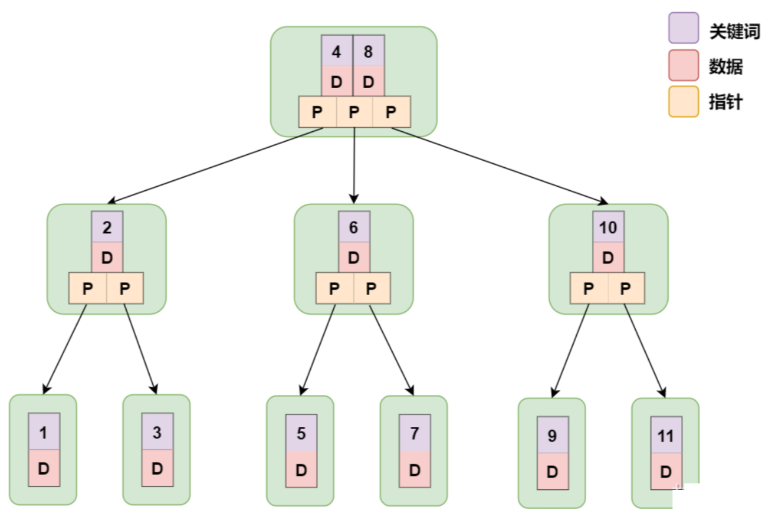
- B 树索引,又称平衡树索引,B Tree能加快数据的访问速度,因为存储引擎不再需要进行全表扫描来获取数据,数据分布在各个节点之中。
- 一棵 m 阶 B Tree 的特性如下:
- 每个结点最多 m 个子结点;
- 所有的叶子结点都位于同一层;
- 每个节点中的元素按关键字key从小到大排列;
- 每个元素子左结点的值都小于或等于该元素,右结点的值都大于或等于该元素。
- 数据库以 B-Tree 的数据结构存储数据的图示如下:
B+Tree索引
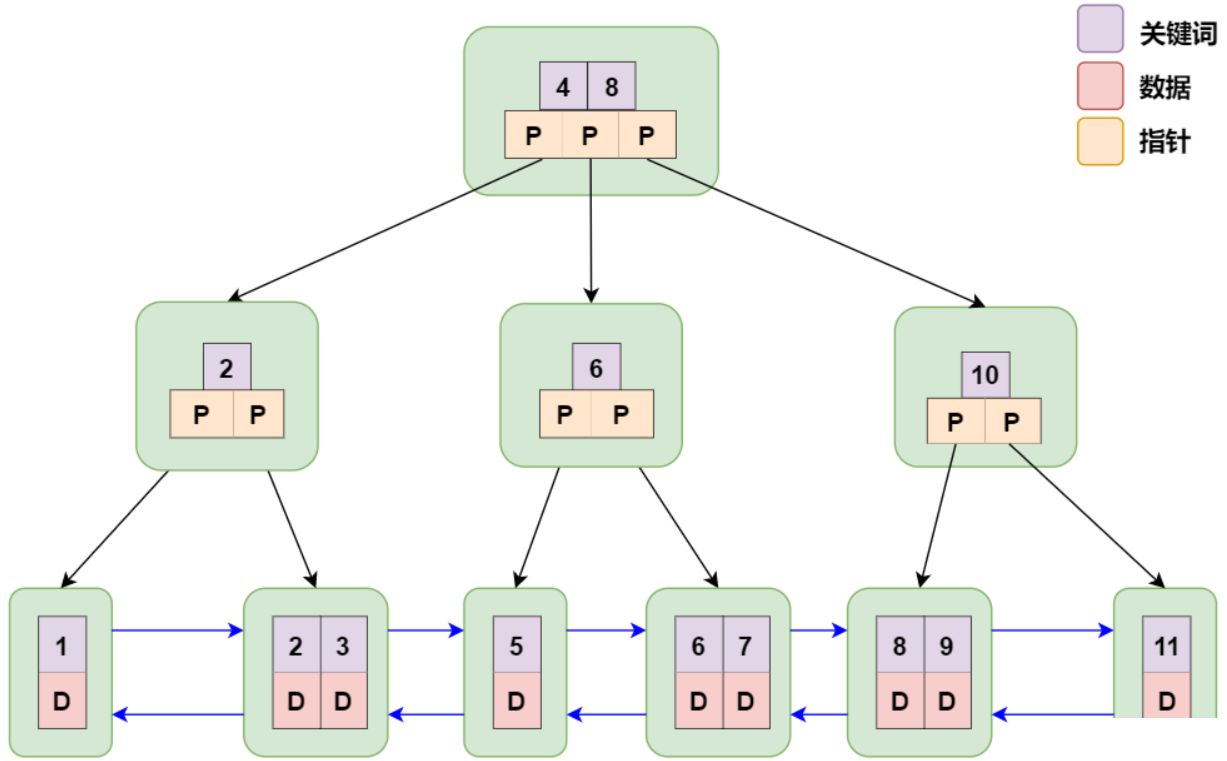
- 是B-Tree的改进版本,同时也是数据库索引所采用的存储结构。数据都在叶子节点上,并且增加了顺序访问指针,每个叶子节点都指向相邻的叶子节点的地址。相比B-Tree来说,进行范围查找时只需要查找两个节点,进行遍历即可。而B-Tree需要获取所有节点,相比之下B+Tree效率更高。
- B+tree性质:
- n棵子树的节点包含n个关键字,不用来保存数据而是保存数据的索引。
- 所有的非叶子结点只存储 关键字key信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接;
- 所有具体数据都存在叶子结点中;
- 所有的叶子结点中包含了全部元素的信息;
- 所有叶子节点之间都有一个链指针。
- 数据库以 B+ Tree 的数据结构存储数据的图示如下:
为什么索引结构默认使用B+Tree,而不是B-Tree,Hash,二叉树,红黑树?
B+树与B树相比:
- B+树的磁盘读写代价更低:B+树的非叶子节点不存贮数据,只存贮关键词key信息,进行数据索引,使每个非叶子节点所能保存的关键字大大增加。这样磁盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对IO读写次数就降低了。
- 更加适合区间查询:B树的数据分布在各个节点之中,当进行范围查找时会出现回旋查找。而B+树的数据都存储在叶子结点中,并且MySQL 索引数据结构对经典的 B+Tree 进行了优化,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的 B+Tree,提高了区间访问的性能,防止回旋查找。
B+树与Hash相比:
- Hash虽然可以快速定位,但是没有顺序,IO复杂度高。
- Hash索引基于Hash表实现,只有Memory存储引擎显式支持哈希索引 。
- Hash索引因为不是按照索引值顺序存储的,就不能像B+Tree索引一样利用索引完成排序。
- 如果有大量重复键值得情况下,哈希索引的效率会很低,因为存在哈希碰撞问题 。
B+树与红黑树相比:
- 红黑树的高度随着数据量增加而增加,IO代价高。
B+树与普通二叉树相比: - 树的高度不均匀,不能自平衡,查找效率跟数据有关(树的高度),并且IO代价高。
- 普通二叉树存在退化的情况,如果它退化成链表,相当于全表扫描。
B+树与平衡二叉树相比:
- 读取数据的时候,是从磁盘读到内存。如果树这种数据结构作为索引,那每查找⼀次数据就需要从磁盘中读取⼀个节点,也就是⼀个磁盘块,但是平衡二叉树的每个节点只存储⼀个键值和数据,树的节点将会非常多,高度也会极其高。如果是 B+ 树,可以存储更多的节点数据,树的高度也会降低,因此读取磁盘的次数就降下来了,查询效率就会更快。
索引的B+树到底有多高?
InnoDB中页的大小一般为16 KB,我们假设一行记录的数据大小为1KB(实际上现在很多互联网业务数据记录大小通常就是1K左右)
- 如果 B+ 树只有1层,也就是只有1个用于存放用户记录的节点,可以存放 16KB / 1KB = 16条数据记录;
- 如果 B+ 树有2层:
- 我们假设主键ID为bigint类型,长度为8字节,而指针大小在InnoDB源码中设置为6字节,这样一共14字节,一个页中共可以存放 16 * 1024 / 14 = 1170个指针,因此可以存放 1170 * 16 = 18720条数据记录;
- 如果 B+ 树有3层:可以存放 1170 * 1170 * 16 = 21902400,大约2000w条数据记录。
所以在InnoDB中B+树高度一般为1-3层,它就能满足千万级的数据存储。在查找数据时一次页的查找代表一次IO,所以通过主键索引查询通常只需要1-3次IO操作即可查找到数据。
与此同时,我们也可以发现索引的B+树高度也跟索引字段的数据类型有关,数据类型越小,索引占用的存储空间就越少,在一个数据页内就可以放下更多的记录,从而减少磁盘 I/O 带来的性能损耗,也就意味着可以把更多的数据页缓存在内存中,从而加快读写效率。
索引的代价(索引是不是越多越好)?
- 空间上的代价
- 每建立一个索引都要为它建立一棵 B+ 树,每一棵 B+ 树的每一个节点都是一个数据页, 一个页默认会占用 16KB 的存储空间,一棵很大的 B+ 树由许多数据页组成,就是很大的一片存储空间,在增删改记录的时候性能就越差。
- 时间上的代价
- 每次对表中的数据进行增、删、改操作时,都需要去修改各个 B+ 树索引。而增、删、改操作可能会对节点和记录的排序造成破坏,所以存储引擎需要额外的时间进行一些记录移位,页面分裂、页面回收啥的操作来维护好节点和记录的排序。
相关推荐






评论




