
索引
没有索引如何查找数据?
在一个页中的查找,分为两种情况:
- 以主键为搜索条件
可以在 页目录 中使用二分法快速定位到对应的槽,然后再遍历该槽对应 分组中的记录即可快速找到指定的记录。 - 以其他列作为搜索条件
对非主键列的查找的过程可就不这么幸运了,因为在数据页中并没有对非主键列建立所谓的 页目录 ,所以 我们无法通过二分法快速定位相应的 槽 。这种情况下只能从 最小记录 开始依次遍历单链表中的每条记录, 然后对比每条记录是不是符合搜索条件。很显然,这种查找的效率是非常低的。
在很多页中的查找,可以分为两个步骤:
- 定位到记录所在的页。
- 从所在的页内中查找相应的记录。
在没有索引的情况下,不论是根据主键列或者其他列的值进行查找,由于我们并不能快速的定位到记录所在的页,所以只能从第一个页沿着双向链表一直往下找,在每一个页中根据我们刚刚唠叨过的查找方式去查找指定的记录。
索引是什么?
索引本质是排好序的数据结构,一种特殊的文件,包含着对数据表里所有记录的引用指针,直接在索引中查找符合条件的选项,加快数据库的查询速度,而不是一行一行去遍历数据后才选择出符合条件的。
优点:
- 可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
- 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
缺点: - 索引是一个文件,它是要占据物理空间的。
- 创建索引和维护索引要耗费时间,具体地,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,会降低增/改/删的执行效率。
MySQL有哪几种索引类型?
- 从数据结构上来划分:哈希索引,B树索引,B+树索引。
- 从功能层次上来划分:普通索引,唯一索引,主键索引,联合索引。
- 普通索引:即一个索引只包含单个列,一个表可以有多个单列索引。
- 唯一索引:索引列的值必须唯一,但允许有空值。
- 主键索引:一种特殊的唯一索引,不允许有空值,一般在建表时同时创建主键索引;
- 联合索引:多列值组成一个索引,专门用于组合搜索。
- 从物理存贮上来划分:聚簇索引,非聚簇索引。
聚簇索引和非聚簇索引?
聚簇索引: 聚簇索引是按照每张表的主键构造一颗B+树,叶子节点中存放的就是整张表的数据,将聚簇索引的叶子节点称为数据页。
c1,c2,c3三列,我们以c1列建立索引,索引树如下图所示: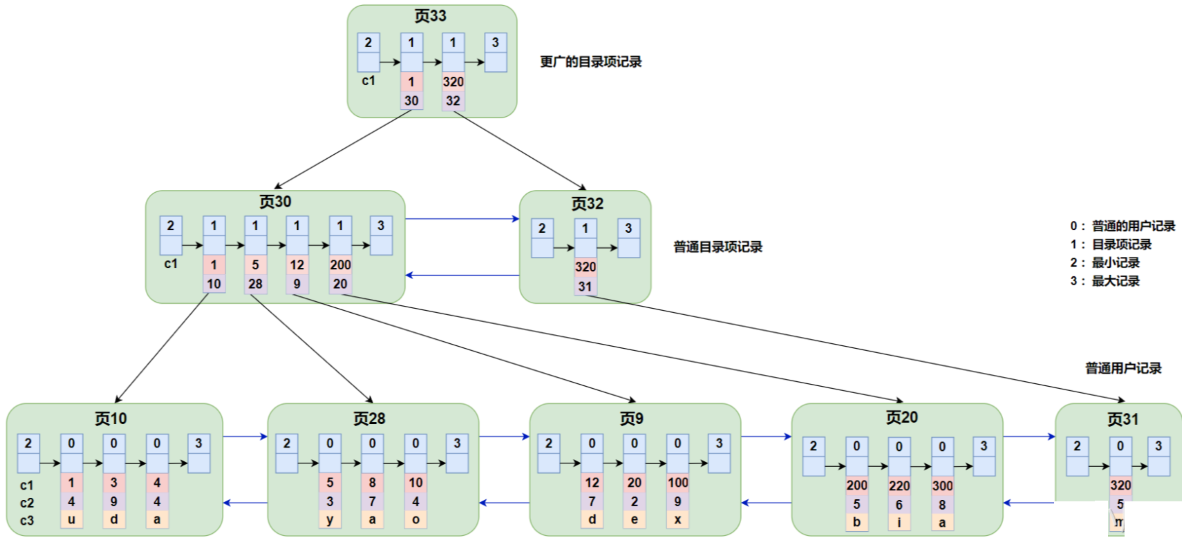
聚簇索引的特点:
聚簇索引不需要我们显式去创建,InnoDB 存储引擎会自动的为我们创建聚簇索引,并且在 InnoDB 存储引擎中, 聚簇索引 就是数据的存储方式(所有的用户记录都存储在了叶子节点 ),也就是所谓的索引即数据,数据即索引。
聚簇索引的优点:
- 数据访问更快,聚簇索引将索引和数据保存在同一个 B+ 树中,因此从聚簇索引中获取数据比非聚簇索引更快;
- 聚簇索引对于主键的排序查找和范围查找速度非常快。
聚簇索引的缺点: - 插入速度严重依赖于插入顺序,按照主键的顺序(递增)插入是最快的方式,否则将会出现页分裂,严重影响性能。
- 更新主键的代价很高,将会导致被更新的行移动,所以对于 InnoDB 表,一般定义主键为不可更新。
- 聚簇索引只能在搜索条件是主键值时才能发挥作用,因为 B+ 树中的数据都是按照主键进行排序的。
非聚簇索引:非聚簇索引叶子节点存储的是主键值,而不是数据的物理地址,所以访问数据需要二次查找,推荐使用覆盖索引,可以减少回表查询。
以c2列作为索引列,建立B+树: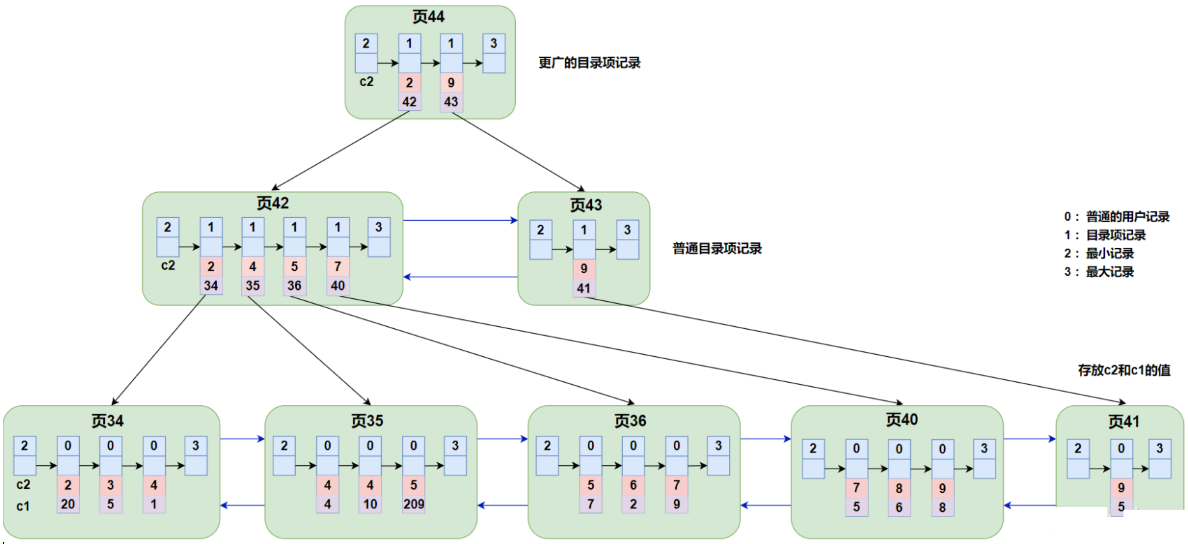
非聚簇索引的特点:
- B+ 树的叶子节点存储的并不是完整的用户记录,而只是 索引列+主键 这两个列的值。
- 以索引列大小排序的 B+ 树只能确定我们要查找记录的主键值,所以如果我们想根据 c2 列的值查找到完整的用户记录的话,仍然需要到 聚簇索引 中再查一遍,这个过程也被称为 回表。
非聚簇索引的优点: - 非聚簇索引由于不存储实际数据,所以实际文件较小,相比于聚簇索引再读取时可以减少磁盘IO。
- 非聚簇索引使用主键作为”指针” 而不是使用地址值作为指针的好处是,减少了当出现行移动或者数据页分裂时辅助索引的维护工作。
非聚簇索引的缺点: - 需要进行回表查询,即查询到对应的聚簇索引之后再通过聚簇索引查询到所需数据。
相关推荐






评论




