hdfs架构及读写数据流程
架构
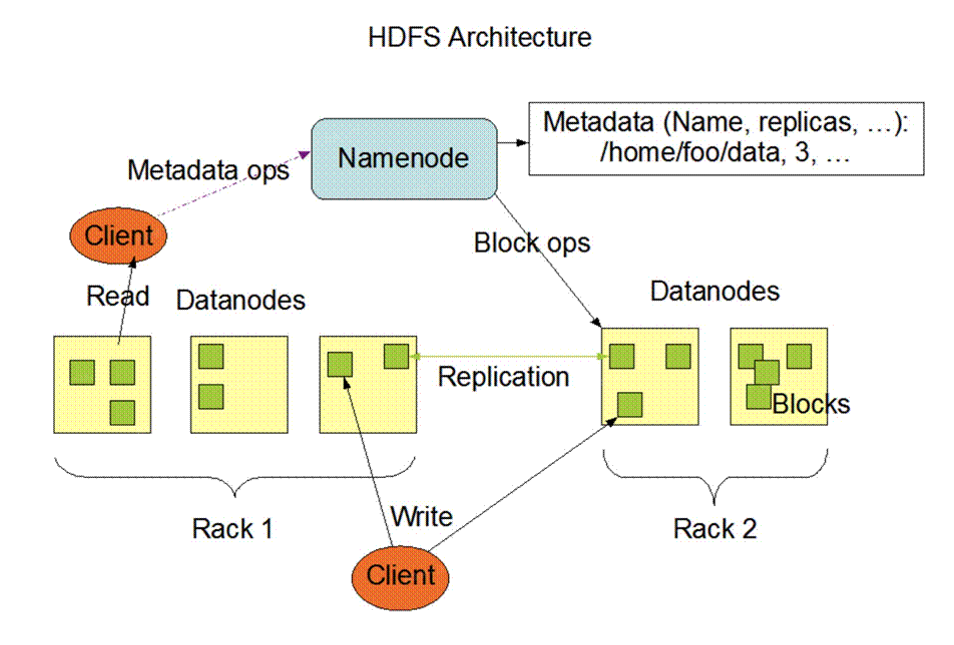
Namenode是HDFS集群主节点,负责管理整个文件系统的元数据,以树形结构维护者集群中所有的文件和目录,所有的读写请求都要经过Namenode。
- a. 处理客戶端请求(读,写,管理);
- b. 管理数据块映射信息;
- c. 管理HDFS的映射空间;
Datanode将HDFS数据以文件的形式存储在本地的文件系统中,它并不知道有关HDFS文件的信息。它把每个HDFS数据块存储在本地文件系统的一个单独的文件中。
- a. 存储实际的数据块;
- b. 进行数据块读写操作;
Client:客戶端
- a. 文件切分。文件上传HDFS的时候,client将文件切成一个个Block,然后进行上传;
- b. 和NameNode交互,获取文件的位置信息;
- c. 和datanode交互,读写数据;
- d. client提供命令来管理HDFS,例如进入安全模式、退出安全模式,格式化等;
SecondaryNameNode:不是NameNode的热备节点,当NameNode退出服务状态时,并不替换NameNode提供服务。
- a. 分担NameNode工作量,定期合并Fsimage和EditsLog,并推送给NameNode;
- b. 可辅助恢复NameNode;
数据分块
HDFS文件块大小
HDFS中的文件在物理上是分块存储(Block),块的大小可以通过配置参数(dfs.blocksize)来规定,默认大小在Hadoop2.x和Hadoop3.x版本中是128M,老版本Hadoop1.x中是 64M。
设置原理
HDFS文件块大小设置主要取决于磁盘传输速率,目前进行寻址的时间约为10ms,即查找到目标block的时间为10ms。
寻址时间为传输时间的1%时,为最佳状态。
因此,传输时间为10ms/0.01=1000ms=1s
目前磁盘的传输速率普遍为100MB/s
因此,block大小为1s*100MB/s=100MB
因为电脑底层数据采用二进制存储,所以目前的block块官方大小设置为128MB。
总结:HDFS文件块大小设置主要取决于磁盘传输速率,生产中采用高速磁盘作为存储介质的可以考虑在HDFS的配置文件中设置dfs.blocksize参数调整block块大小。
思考:块设置太大或太小或怎样?
HDFS的块设置太小,会增加寻址时间,程序一直在找块的开始位置;
如果块设置的太大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。导致程序在处理这块数据时,会非常慢,并行度也降低。
写数据流程
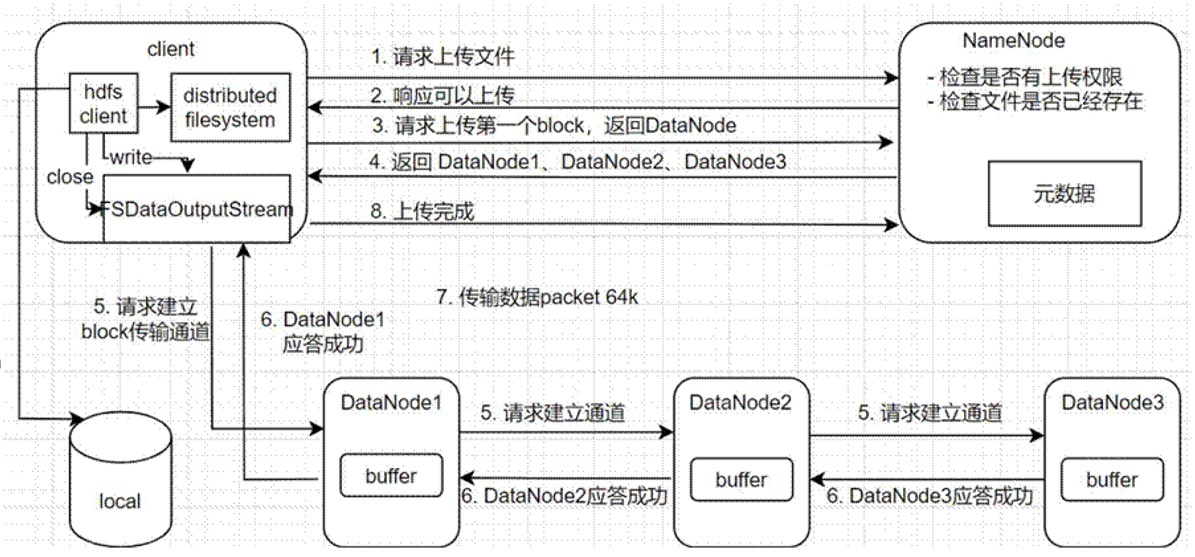
- 客戶端通过DFS向NN请求上传文件,NN进行检查(权限,文件是否已存在);
- NN返回是否可以上传;
- client请求第一个Block上传到哪几个DN上;
- NN返回 3 个DN节点;
- 客戶端通过FSDataOutputStream请求DN1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成;
- dn1、dn2、dn3逐级应答客戶端;
- 客戶端开始上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,
dn1收到一个packet就会传给dn2,dn2传给dn3,dn1每传一个packet会放入一个应答队列等待应答; - 当一个block传输完成后,客戶端再次请求NN上传第二个blcok的服务器;(重复执行 3 -7步骤)
- 网络拓扑节点距离计算
- 在HDFS写数据的过程中,NN会选择距离待上传数据最近距离的DN接受数据。
- 如何计算这个最近距离呢?
- 节点距离:两个节点到达最近的共同祖先的距离总和。
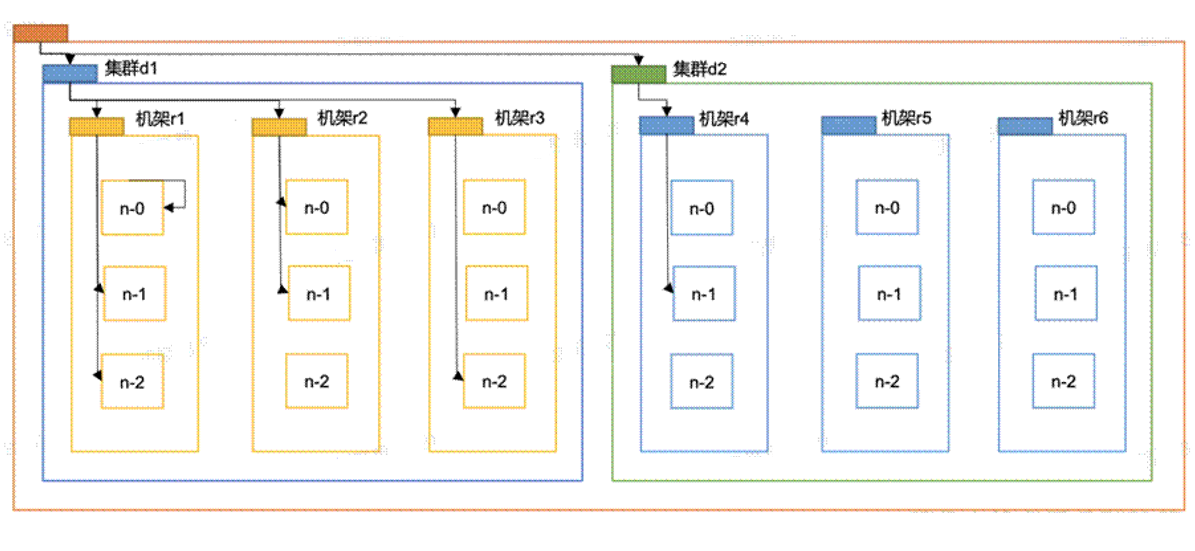
distance(/d1/r1/n0,/d1/r1/n0)=0(相同节点)
distance(/d1/r1/n1,/d1/r1/n2)=2(相同机架,不同节点)
distance(/d1/r2/n0,/d1/r3/n1)=4(相同数据中心,不同机架)
distance(/d1/r2/n1,/d2/r4/n1)=6(不同数据中心)
机架感知-副本节点选择
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
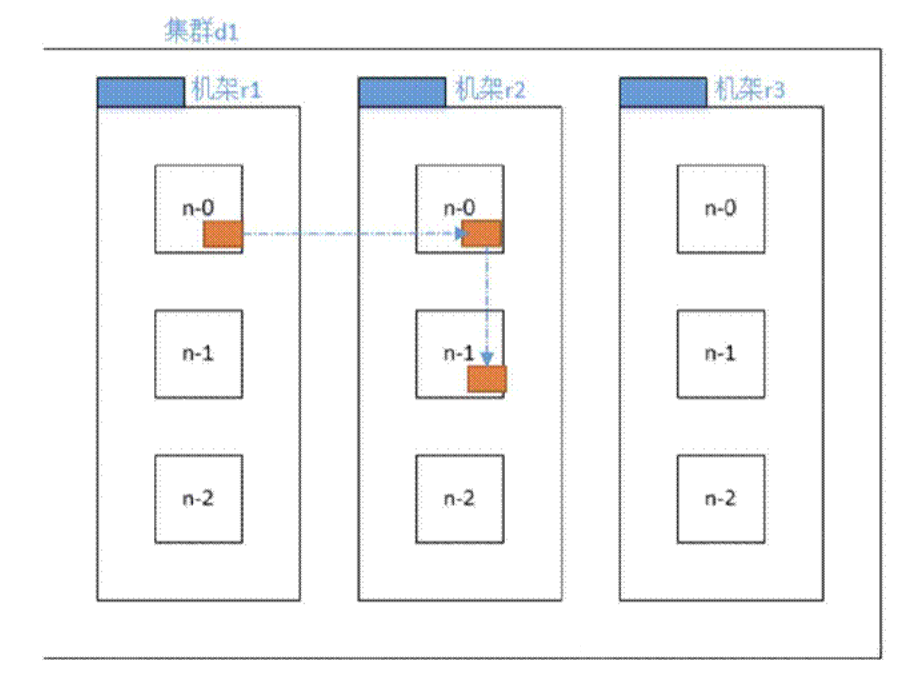
第一副本:放置在上传文件的DN上(就是执行‘hadoopfs-put文件名’上传文件命令的机器上,本
地文件上传到同一台机器自然要快一点),如果是集群外提交,则随机挑选一台;
第二副本:放置在第一副本不同机架的不同节点上;
第三副本,放置在第二副本相同机架的不同节点上;其他更多副本:随机放置在节点中。
读数据流程
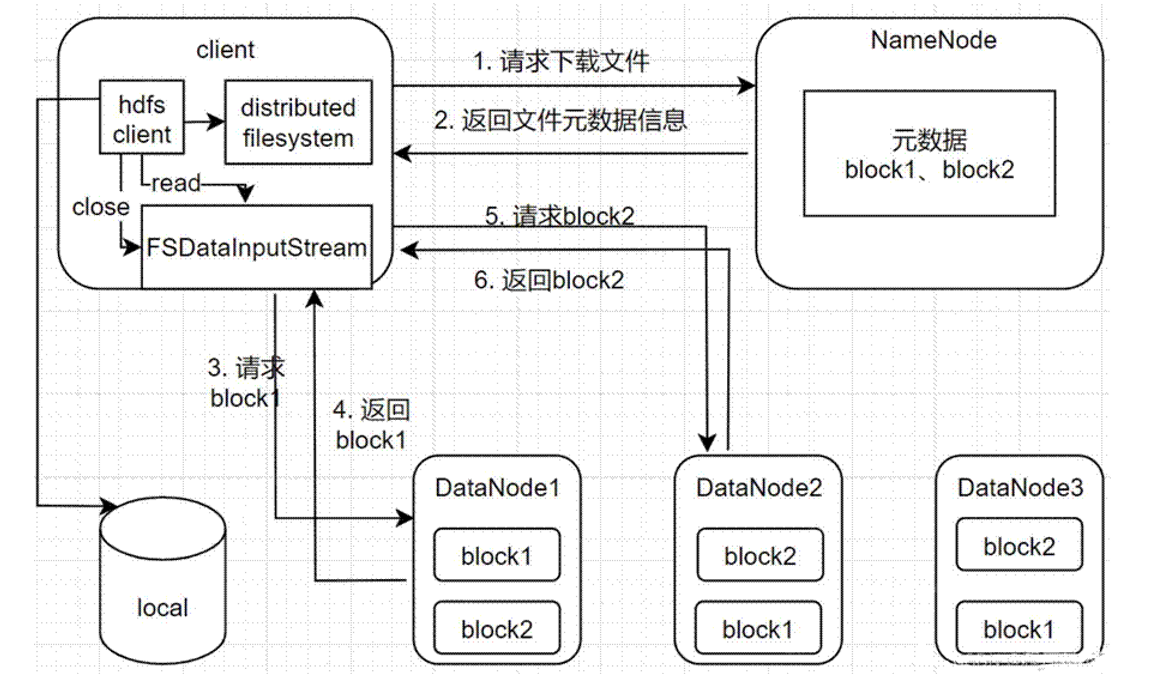
- 客戶端通过DFS(DistributedFileSystem)向NameNode请求下载文件,NameNode通过查询元数
据,找到文件块所在的DN地址; - 选取一台DN(就近原则,然后随机)服务器,请求读取数据;
- DN开始传输数据给客戶端(从磁盘里读取数据输入流,以Packet为单位来做校验);
- 客戶端以Packet为单位接收。